How AI Optimizes Resources and Enhances Performance in Distributed-Queues

This year, one of the leading online ticketing platforms faced a significant system failure during ticket sales for a highly anticipated event. Despite being designed to manage high traffic, the platform struggled to cope with an unprecedented influx of users, resulting in app crashes and considerable downtime. Initial analysis suggested that the issue stemmed from a surge in traffic, often referred to as the "thundering herd" effect, which overwhelmed the system. Let's determine why this happened, explore the technologies that can be used, and identify how it could have been dodged altogether.
Before diving into the role of AI, it's essential to understand the concept of distributed queues. But first, let's start with the basics: What is a messaging queue?
A messaging queue is a form of asynchronous communication used in serverless and microservices architectures. It allows messages or data to be sent between different parts of a system without requiring the sender and receiver to interact with the message simultaneously. Think of a messaging queue like an email inbox. When you send an email, it goes to the recipient's inbox. The recipient can read and respond to the email whenever they check their inbox, not necessarily when you sent it. This way, both you and the recipient don't need to be online at the same time.
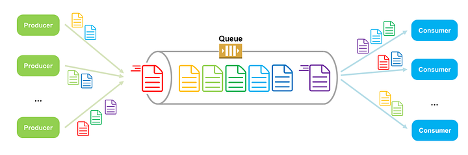
Expanding on this concept, a distributed queue is designed to operate within distributed systems, which consist of multiple interconnected computers working together to achieve a common goal. These systems are known for their ability to scale horizontally, handle failures gracefully, and provide high availability and reliability. In a distributed queue, the queue is spread across multiple nodes in the system. This distribution helps balance the load, improve fault tolerance, and ensure the system can handle a large number of messages efficiently. Each node in the distributed system can enqueue and dequeue messages, with the system ensuring reliable and timely message delivery, even if some nodes fail or become temporarily unavailable.
In distributed systems, tasks or messages need to be processed by multiple servers. A distributed queue is a data structure that holds these tasks and ensures they are processed in an orderly and efficient manner. Examples of distributed queue systems include Apache Kafka, RabbitMQ, and Amazon SQS.
The challenges of managing distributed queues
Managing distributed queues involves several challenges:
- Load Balancing: Ensuring that tasks are evenly distributed across servers to prevent them from becoming a bottleneck.
- Scalability: Handling an increasing number of tasks without degrading performance.
- Fault Tolerance: Ensuring the system remains operational even if some servers fail.
- Latency: Minimizing the time it takes for a task to be processed.
How AI optimizes distributed queues
AI offers several techniques to address these challenges and optimize the performance of distributed queues:
- Predictive Analytics for Load Balancing: AI uses historical data to predict and manage future loads, preventing bottlenecks and proactively allocate resources to ensure that tasks are evenly distributed across servers.
- Dynamic Resource Allocation: Traditional systems often allocate resources based on static rules, which can lead to inefficiencies. On the other hand, AI adjusts resources in real-time based on server performance, optimizing throughout and reducing latency.
- Anomaly Detection for Fault Tolerance: AI identifies system anomalies, allowing preemptive actions like task rerouting or resource scaling to maintain fault tolerance.
- Intelligent Task Scheduling: AI schedules tasks by considering priority, server load, and network latency, ensuring efficient processing.
- Auto-scaling for Scalability: AI automatically scales resources based on demand, handling peak loads efficiently without over-provisioning during low demand.
How could AI have helped online ticketing platform avoid the "thundering herd" effect during the most anticipated show?
- Problem: The sudden surge in traffic overwhelmed the system, leading to app crashes and downtime.
Solution: AI-driven predictive analytics can analyze historical data from previous high-demand events to forecast traffic patterns. By predicting the surge in user activity, the system can proactively allocate resources and balance the load across multiple servers. This pre-emptive approach ensures that no single server becomes a bottleneck, hence maintaining system stability. - Problem: Static resource allocation rules may not be sufficient to handle sudden spikes in demand.
Solution: AI can dynamically adjust resources in real-time based on current server performance and traffic conditions. For instance, during the peak ticket sales period, AI can allocate additional computing power and bandwidth to the servers handling the most traffic. This real-time adjustment helps optimize throughput and reduce latency, ensuring a smoother user experience. - Problem: The system failed to handle the unexpected surge, leading to crashes and downtime.
Solution: AI-powered anomaly detection can continuously monitor the system for unusual patterns or behaviours. When an anomaly is detected, such as an unexpected spike in traffic, the AI can trigger pre-emptive actions like task rerouting to less busy servers or scaling up resources. This proactive approach helps maintain fault tolerance and prevents system failures. - Problem: Inefficient task scheduling can lead to delays and uneven load distribution.
Solution: AI can optimize task scheduling by considering factors such as task priority, current server load, and network latency. By intelligently distributing tasks, AI ensures that high-priority tasks (like processing ticket purchases) are handled promptly, while also balancing the load across the system. This results in more efficient processing and a better user experience. - Problem: The system struggled to scale up quickly enough to handle the peak load.
Solution: AI-driven auto-scaling can automatically adjust the number of active servers based on real-time demand. During the peak ticket sales period, AI can rapidly scale up resources to handle the increased load, and then scale down during periods of low demand to optimize costs. This ensures that the system can handle peak loads efficiently without over-provisioning resources during off-peak times.
Conclusion
AI can significantly enhance the performance and reliability of distributed queue systems, addressing challenges like load balancing, scalability, fault tolerance, and latency. For online ticketing platform, AI-driven solutions such as predictive analytics, dynamic resource allocation, anomaly detection, intelligent task scheduling, and auto-scaling could have mitigated the "thundering herd" effect during the event. By proactively managing resources and optimizing system performance in real-time, AI ensures a seamless user experience even during high-demand events.

Mohit Wayde | RIEPL
October 29, 2024