
Introduction
Product Matching in e-commerce refers to identifying exact or similar matches to certain set of query products from among the catalog products in e-commerce database. It relies on using one or more features of a product such as product title, description, category, product image(s), size, color etc. The query products could refer to internal or external products such as those sold by competitors. Product matching powers various use cases related to price optimality, item product linking, search aggregation, product recommendations and leads to improved catalog quality. There are many intricacies to building a high quality product matching pipeline which is scalable and has acceptable guarantees on the match performance. In this post, we describe an end-to-end ML system to match two products utilizing both textual attributes and images of a product. We touch upon some of the challenges that we encountered and describe modeling approaches using Deep Learning.
Product Matching with Textual Features
The textual information on products consists of title, description, category path, attribute::value pairs etc. For simplicity, we describe the flow assuming only product titles. However, the pipeline can be easily extended to include other textual information.
Data Flow
We illustrate the data flow below. The product to be matched passes through a stage 1 search, which returns candidate result set. The re-ranking model rescores the results returned by the search system in a refinement step
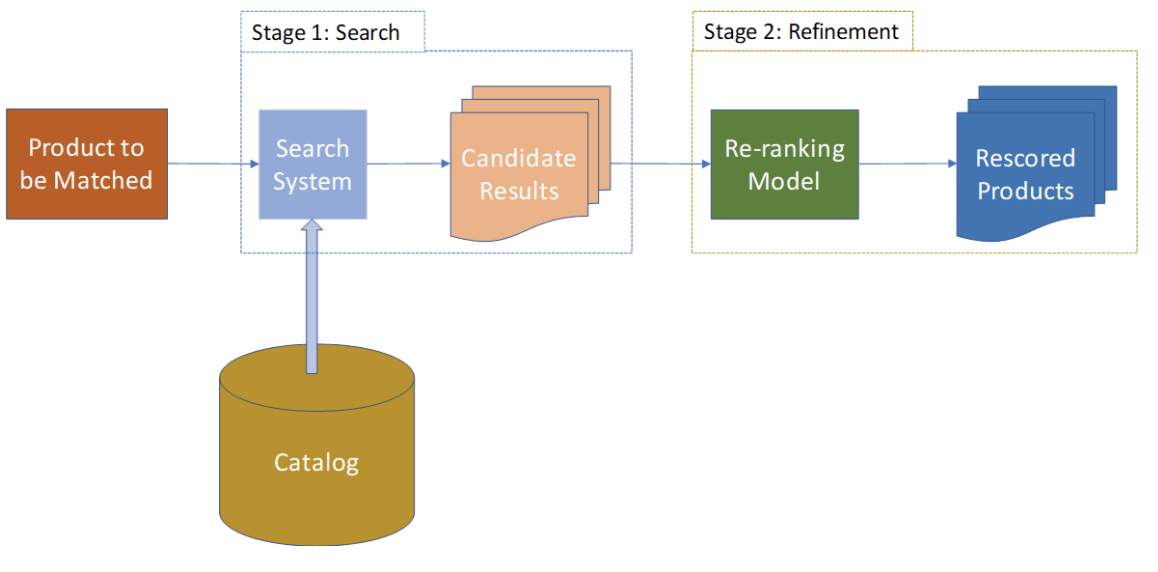
Search Re-ranking Models
The objective of the search re-rank model is to re-rank the search results to produce more relevant results in the top of the result set. We use top-1 accuracy as a metric to gauge the performance of various models. Top-1 accuracy refers to the accuracy of the first result returned by the re-rank system. This metric was chosen since it was more tied to the particular business use-case that we are solving.
What is the need for a re-rank model?
Due to latency constraints, it is an established practice to have a more coarse but faster search in stage 1 followed by a more expensive re-ranking step to offer better search relevancy. See https://en.wikipedia.org/wiki/Learning_to_rank for more on this topic. Moreover, the top-1 accuracy of the stage 1 search system fails to meet the target accuracy requirements for the business use-case that we being targeted.
Modeling the problem as item to item similarity
Although the problem we are trying to solve asks for a re-ranking of the results of the first search system, in order to train a ML model that does re-rank, we need a training dataset that consists of annotated ranked order of the search results, an extremely expensive and time consuming dataset to procure.
We model the problem as computing the similarity of two item titles. The predicted score is used to re-rank the result set. It is desirable to have a higher score for two products that are nearly a match and a lower score for two products that are not a good match.
Modeling Approaches

Broadly speaking, there are two different ways to model the re-rank problem. In one of the approaches, we build a deep learning model which takes in the two product titles and computes the similarity score. In the other, we compute a fixed dimensional embedding, that is used to compute similarity of items via a similarity measure such as cosine similarity. The latter approach goes by the name of Deep Metric Learning in ML literature. We compare the two approaches in the table below.
Table 1: Comparison of modeling approaches: Pros and Cons
| Embedding based | Pretrain-Finetune Deep Learning model |
| Static embedding for products | Each Query-Result pair is separately scored |
| Limited model capacity | Large model capacity |
| Compute Friendly (for model inference) | Compute Heavy, GPU required for large models |
| Performance varies based on problem complexity | Good Performance across complex problem spaces |
| Eg: Use a pre-trained model with Contrastive Loss or Triplet Loss | Eg: BERT, RoBERTa with Cross entropy loss |
Due to the large model capacity and higher performance on our internal datasets, we chose to go with the Pretrain-Finetune Deep Learning model approach. We have used BERT based architectures and further fine-tuned on our datasets. We note that the embedding based approach is also a good choice for many problems of this nature and ultimately it boils down to specifics of the datasets and the accuracy requirements of the use-cases that are being targeted.
Building ML applications in the age of pre-trained models
Pre-trained models have played a large role in the democratization of AI/ML applications over the past several years. The following post crystallizes the distinction between traditional software programming and programming for data/ML applications.
Below, we summarize some of the challenges and learnings we accumulated on the way. Unless otherwise stated, we assume a BERT-Large ML model that is finetuned to our dataset.
Separate models for each category
We found that training a single model for all categories typically works better. With the recent advances in transfer learning for NLP, models can learn patterns from a resource rich category and generalize it to other categories with less data. Moreover, maintaining and deploying a separate model/category is difficult and performance is poor for categories with less training data.
Using Descriptions + Attributes
It is a general perception among ML practitioners that more data leads to better models and people go one step further and say, more data is more important than better models. However, it is prudent to check whether the additional data being included is adding signal and not noise to the data. Borrowing some terminology from communications literature, we define the SNR as the ratio of signal to noise in the input. In the context of ML applications, sometimes adding more data leads to increase in the noise, leading to a degrade in performance.
We observe that descriptions are noisy leading to lower performance. These would need further processing to reduce the inherent noise levels and make it usable for further downstream tasks. To illustrate this, take a look at the following description for "Dark Viking Dress Women's Costume,"
"Are you ready to rule the Viking horde? The men have had the run of things for long enough, so we think it's time for a shieldmaiden to break the ranks, challenge the king, and finally grab the top spot in the Viking hierarchy. There's no saying what could happen when you're in charge, but first things first... we're going to have to upgrade your look! Since your battle garb isn't quite going to cut it when you're challenging for the throne, let us suggest trying out this Dark Viking Dress for your future reign! This elegant full length dress will have you standing out whether you're running the kingdom or setting sail across the sea to plunder and raid. The fur shawl is sure to let everyone know that you still know how to kick butt, but with elegant brocade trim, nordic inspired jewelry, and a stunning red sash to finish off the ensemble, we won't blame you if you just want to sit back in the lap of luxury and let the berserkers and shieldmaidens do all of the dirty work for you. This HalloweenCostumes.com exc…"
Also, most derived attributes from product titles provided no extra information as the model has already factored these in.
Imbalanced Availability of Attributes
Some important attributes such as size and color are missing from product titles. It is sometimes encoded as part of the web page, where there is a drop down box to select color which is not accessible to the model. At other times, it is wholly missing from the page itself. In these cases, the ML model ends up retrieving a different variant of same product where either size or color differs.
Preference for Shorter Titles
Some DL models we have trained seem to prefer shorter titles where all words were present in query, over other potentially more relevant products with longer titles.
Query Title: Nike Mens Dry Classic Jersey White/Black MD
| Response Title | Predicted Score |
| Nike Classic Men’s Jersey | 0.967432 |
| Nike Dry Classic Jersey (Black/White) Men's Clothing | 0.94321 |
On closer inspection, analyzing the training data revealed the existence of a number of short titles where in fact the products were a match for the query. Solution: remove such low quality positive samples from training data through a pre-processing step.
Large models easily Overfit
We observe that larger pre-trained models such as BERT easily overfit to the training dataset. Below, we see that continuing to train the model leads to lower performance. Hence, we suggest to maintain a validation set and stop training when the validation metric fails to improve.
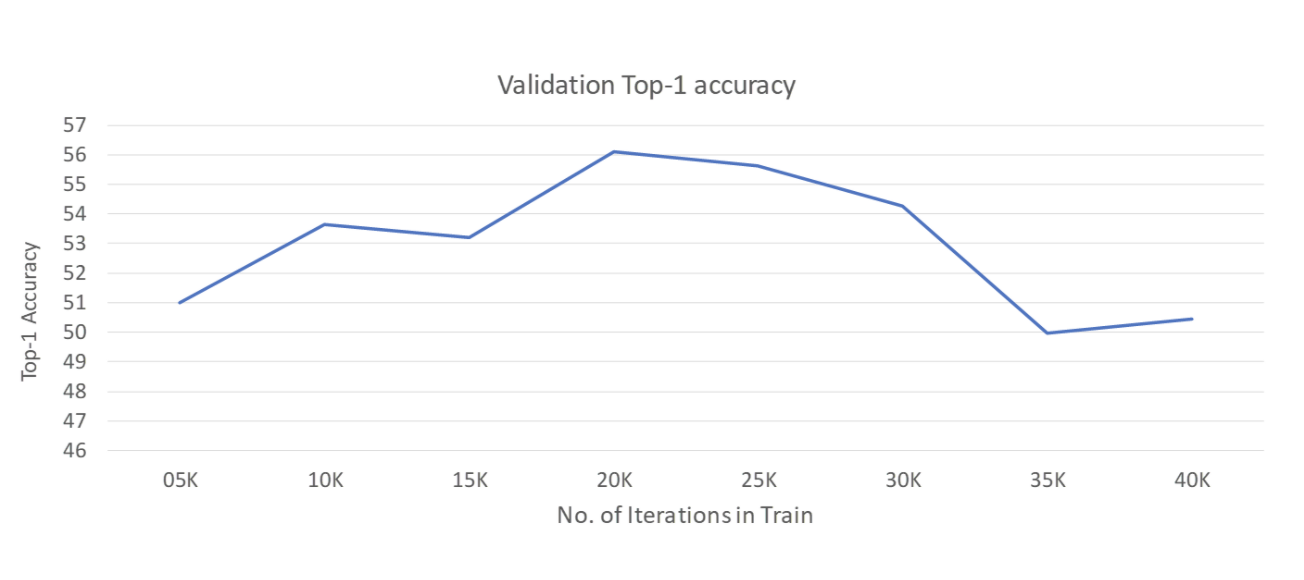
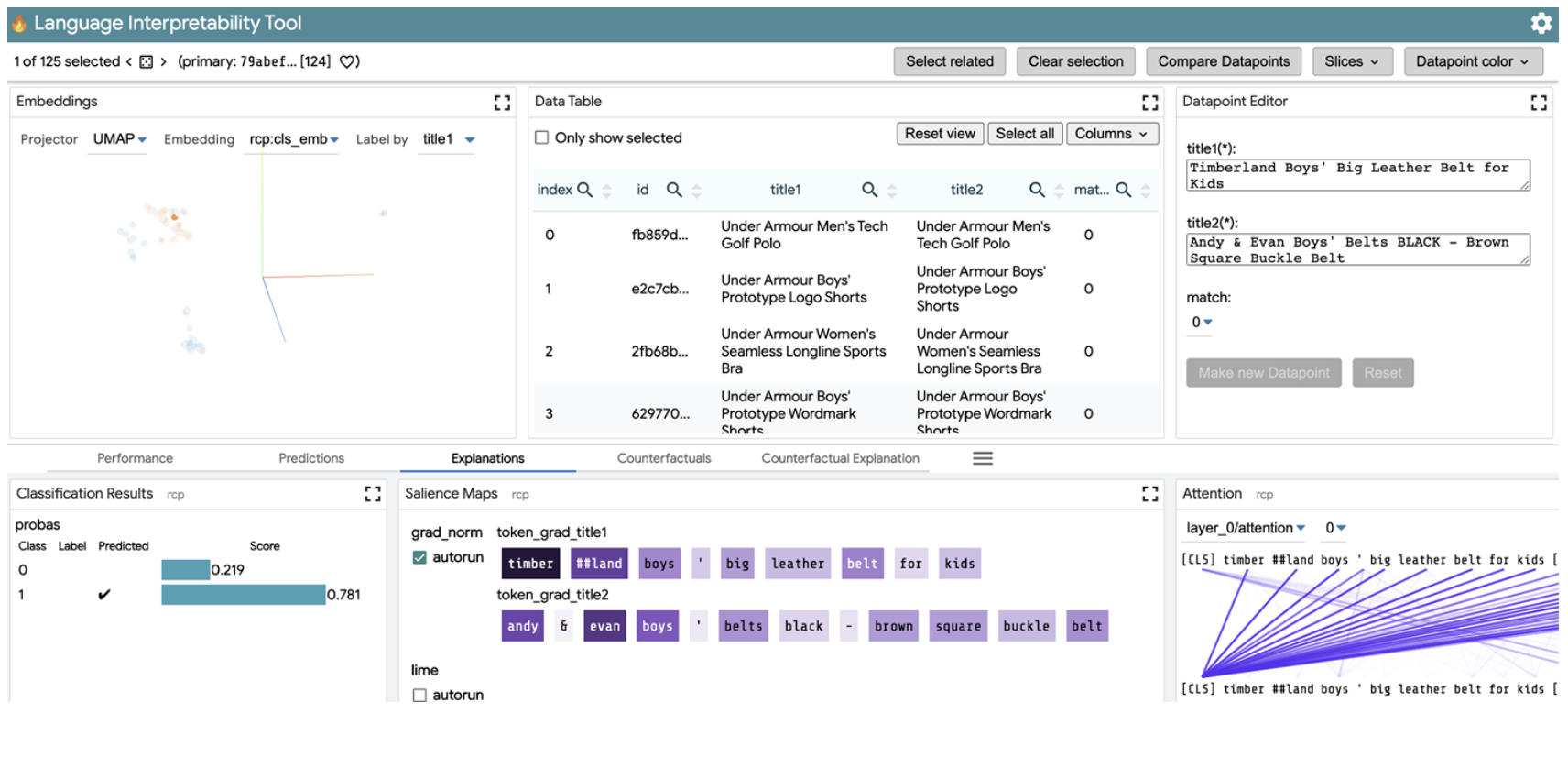
Visualization
The Language Interpretability Tool (LIT) by Google developers helps in visualization and understanding of NLP models as seen below.
Inherent challenges with Product Titles
Brands and merchants often release different product lines with similar sounding product titles. This means, we end up with matching vastly different products compromising the match quality. In the following sections, we talk about using product images to solve this issue.
Opportunity for Utilizing Product Images
The image modality provides a rich set of features which can be used to identify exact or similar products, or to reject non-similar ones. To illustrate this point, we analyze some of the errors by the Title Similarity ML models. These products were predicted to be a match by the ML model, however, belonged to different products.
Errors occur when titles are nearly similar with differences in one or more of
- Zip: full zip, ½ zip, ¼ zip
- Hoodie: with, without
- Sleeve: full sleeve, ¾ sleeve, half sleeve, sleeve-less
- Garment type: Jacket / Sweatshirt / Vest etc.
- Bundle (E.g.: set of 3) vs Single
- Many other patterns and numerous corner cases
Modeling Approaches
Some of the same appraoches that we discussed for Text models above, apply here as well, namely the deep learning model and the deep metric learning appraoches.. We note some differences here. Although storing, pre-processing and including it as part of input for text models is relatively easy, this is not the case for image data. High resolution product images pose another problem and the benefits arising out of using a higher resolution image has to be traded off against the higher compute and storage costs.
Due to these considerations, it makes sense to compute a fixed dimensional embedding for each product. The similarity between images is then computed using a similarity measure such as cosine similarity. In the following sections, we describe one such approach.
Deep Metric Learning
The objective here is to have similar data close to each other in the embedding space, and dissimilar data away from each other.

Triplet Networks
Triplet networks consist of a training process which includes as input 3 entities, an anchor, a positive sample and a negative sample as shown below. The inputs are passed through identical networks with weight sharing or in other words, the same network is reused for all 3 inputs resulting in a fixed dimensional embedding.

Let d(x, y) = distance between the embeddings x and y using a certain similarity measure. Training proceeds with the aim of reducing the distance between the anchor and positive samples and the opposite for anchor and negative samples. We expect a well trained model with triplet loss to have the following behavior
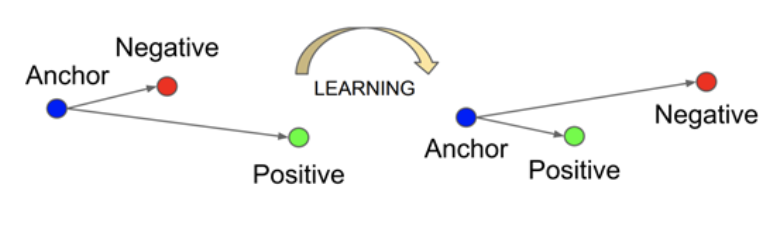
Image similarity using Triplet Networks
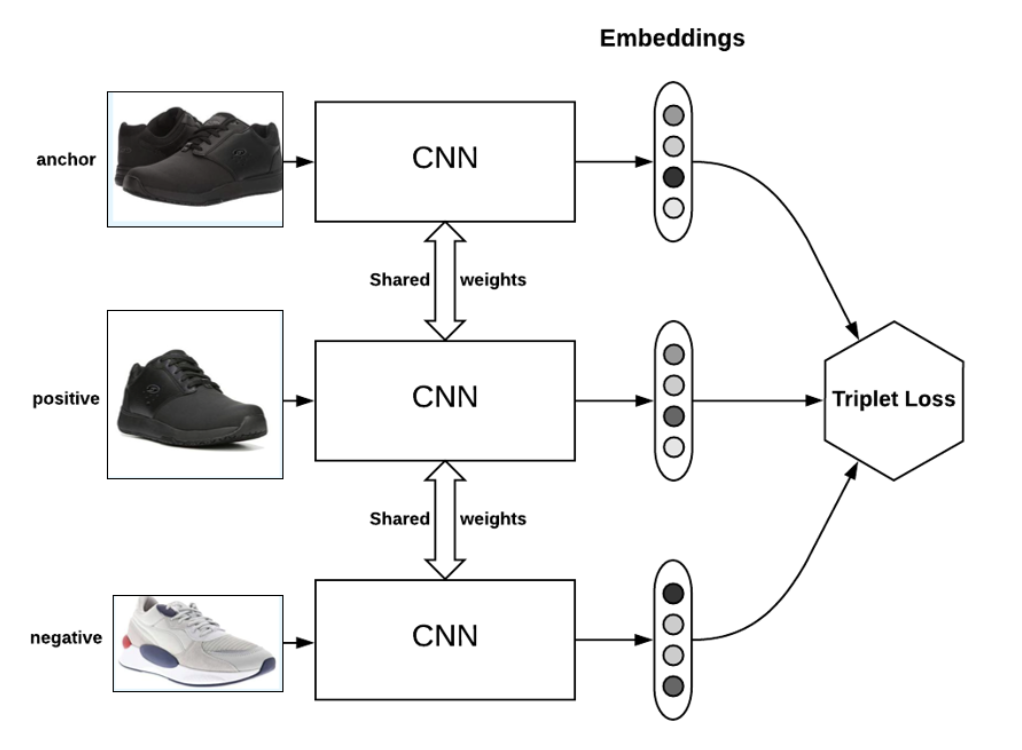
The loss function is defined over anchor, positive and negative samples ((a, p, n) respectively):
L(a, p, n) = max(d(a,p) − d(a, n) + 𝛼, 0) where α is a margin parameter.
Triplet Mining
Triplet Mining refers to methods for choosing triplets. We refer the reader to for a description of various techniques used here.
Computing the similarity score
In the end, we will have image embeddings for each product image. These can be used to compute the similarity score of two products using say cosine similarity etc. These scores can be augmented with the scores from text models to architect a high quality product matching pipeline.
Another approach which also looks attractive is to employ multimodal techniques. Here, the idea involves the computation of a joint embedding from text and image(s) of a product, which is then used to compute similarity of products.
Useful Links
- LIT - https://pair-code.github.io/lit/
- Triplet Loss and Triplet Mining - https://omoindrot.github.io/triplet-loss
- https://en.wikipedia.org/wiki/Learning_to_rank

