
Jarvis : Sir, it appears his suit can fly.
Tony Stark : Duly noted. Take me to maximum altitude.
Jarvis : With only 19% power, the odds of reaching that altitude...
Tony Stark : I know the math! Do it!
If you are a fan of Iron Man movie, you would have seen Tony Stark’s personal AI assistant J.A.R.V.I.S perform complicated tasks for him. Have you ever wondered if you could create a J.A.R.V.I.S for yourself? With the advent of LLMs and LLM agents, it seems that this task is not impossible.
If you closely observe the above dialogue, you can see that each statement has got its own sub-tasks to be performed. For example, “Sir, it appears his suit can fly” statement would require JARVIS to track the person, and understand that activity performed by the person is “fly”. This involves JARVIS to have strong computer vision skills, along with some strong natural language skills.
With the advancement of deep learning and large datasets, we currently have powerful models showcasing human-like performance. The emergence of LLMs have made decoding of languages easier as well. LLM agents, or Language Learning Model agents, are AI models designed to understand, perform multiple multimodal tasks and generate human- like text based on the input they receive. The advancement of LLM agents show that the application of LLMs can be extended beyond writing essays, poems, stories and programs. An LLM agent has LLM as the agent’s brain. The agent uses prompts to plan the task, connects with a memory and uses tools to perform the task in the generated task order.
The Microsoft recently published a paper, HuggingGPT, where LLM acts as a controller to plan the tasks, select models from HuggingFace model-store and create responses combining all predictions from the selected models. HuggingFace is a website that provides numerous tools and models for researchers and developers. HuggingGPT uses ChatGPT as the task planner to select models from the HuggingFace repository and summarize the response based on the model predictions. The biggest advantage of this technique is that we can combine multi-modal models, specifically made for speech, computer vision or language tasks.
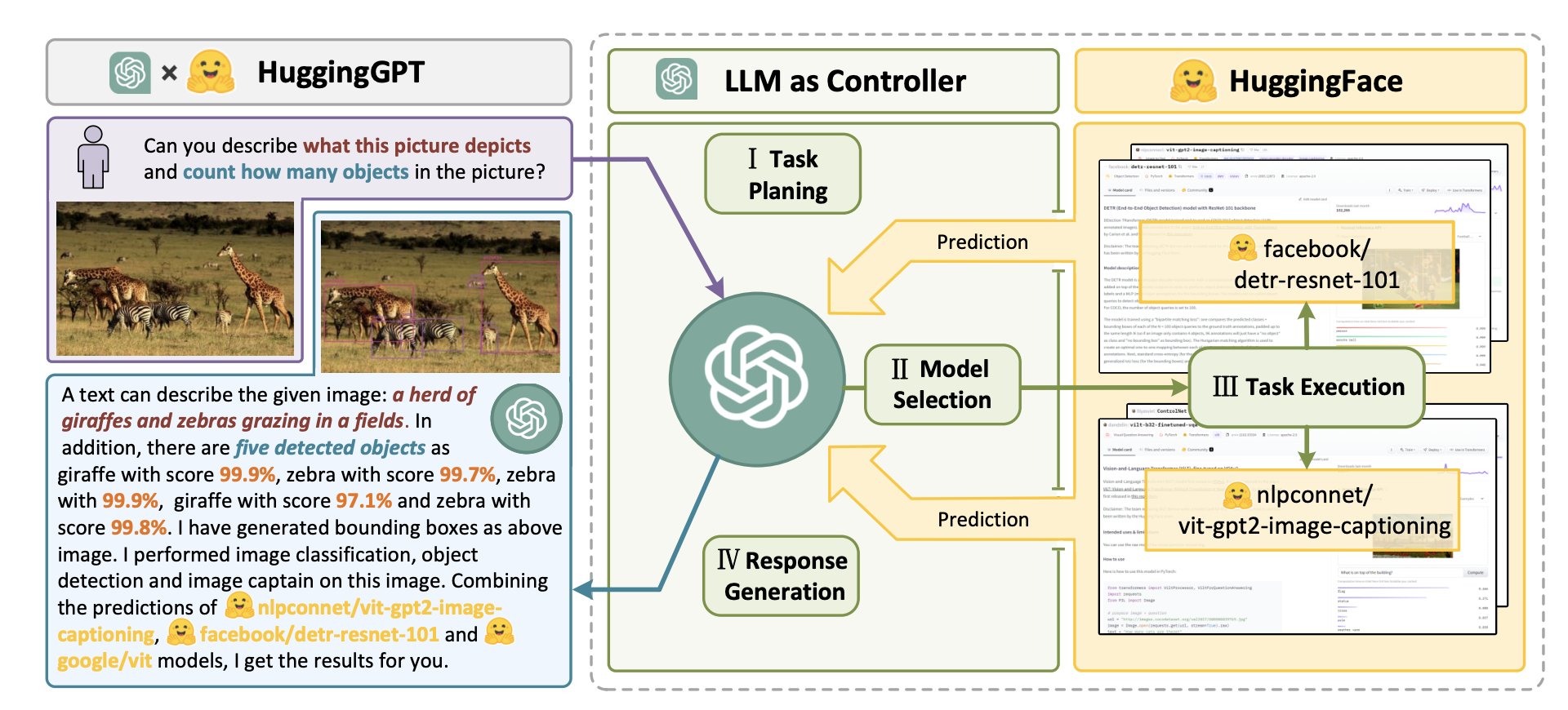
The system consists of 4 stages:
- Task planning
- Model Selection
- Task Execution
- Response Generation
Task planning:
This module parses the user input into multiple tasks. A prompt is designed
to generate a list of task JSONs. This list of JSONs provide information about the order of
task and the arguments passed into the function. The output also provides the dependency of
tasks on other tasks. The prompt used by HuggingGPT to perform planning is as follows:
```The AI assistant can parse user input to several tasks: [{"task": task, "id", task_id, "dep": dependency_task_ids, "args": {"text": text, "image": URL, "audio": URL, "video": URL}}].The "dep" field denotes the id of the previous task which generates a new resource that the current task relies on. A special tag "-task_id" refers to the generated text image, audio and video in the dependency task with id as task_id. The task MUST be selected from the following options: {{ Available Task List }}. There is a logical relationship between tasks, please note their order. If the user input can't be parsed, you need to reply empty JSON. Here are several cases for your reference: {{ Demonstrations }}. The chat history is recorded as {{ Chat History }}. From this chat history, you can find the path of the user- mentioned resources for your task planning.```
Some sample outputs for a few questions are as follows:
```
1. Can you tell me how many objects in e1.jpg?
[{"task": "object-detection", "id": 0, "dep": [-1], "args": {"image": "e1.jpg" }}]
2. In e2.jpg, what’s the animal and what’s it doing?
[{"task": "image-to-text", "id": 0, "dep":[-1], "args": {"im age": "e2.jpg" }}, {"task":"image-cls", "id": 1, "dep": [-1], "args": {"image": "e2.jpg" }}, {"task":"object-detection", "id": 2, "dep": [-1], "args": {"image": "e2.jpg" }}, {"task": "visual-question-answering", "id": 3, "dep":[-1], "args": {"text": "what’s the animal doing?", "image": "e2.jpg" }}]
```
Model selection:
After parsing the task, HuggingGPT select the most appropriate model for
each task in the parsed task list. The description of the models in HuggingFace repository are
used to match the appropriate model. An LLM, again, is presented with the list of models to
choose from. Following is the prompt used for model selection.
``` Given the user request and the call command, the AI assistant helps the user to select a suitable model from a list of models to process the user request. The AI assistant merely outputs the model id of the most appropriate model. The output must be in a strict JSON format: "id": "id", "reason": "your detail reason for the choice". We have a list of models for you to choose from {{ Candidate Models }}. Please select one model from the list. ```
The candidate models selected will have the format:
```
{"model_id": model id #1, "metadata": meta-info #1, "description": description of model #1}
{"model_id": model id #2, "metadata": meta-info #2, "description": description of model #2}
· · · · · · · · ·
{"model_id": model id #K, "metadata": meta-info #K, "description": description of model #K}
```
Task execution:
Once a specific model is assigned to a parsed task, the next step is to perform model
inference. The arguments from the previous prompts are passed into the selected models and
the predictions are obtained.
Response Generation:
After completing all task executions, HuggingGPT proceeds to generate the final responses.
In this stage, HuggingGPT consolidates all the information from the previous stages,
including the list of planned tasks, the selected models for the tasks, and the inference
results of the models, into a concise summary. HuggingGPT enables LLM to receive
structured inference results as input and generate the output in a friendly human language.
Following is the prompt for generating the final result:
```With the input and the inference results, the AI assistant needs to describe the process and results. The previous stages can be formed as - User Input: {{ User Input }}, Task Planning: {{ Tasks }}, Model Selection: {{ Model Assignment }}, Task Execution: {{ Predictions }}. You must first answer the user's request in a straightforward manner. Then describe the task process and show your analysis and model inference results to the user in the first person. If inference results contain a file path, must tell the user the complete file path. If there is nothing in the results, please tell me you can’t make it.```
Thus the LLM agent provides you the result in text format. The agent also provides the reasoning behind the answer too.
There are quite a few challenges still faced by LLM agents
- Hallucination: This is a known problem in LLM. Due to hallucination, we often do not get similar solutions across multiple prompts. This causes the integration of different modules to be quite difficult.
- Long context window: LLM agents need to use long prompts, along with appended results from previous prompts. This causes the requirement of a long context window, which is very expensive and less accurate.
Despite all the challenges, it is very impressive that we can have an A.I assistant that combines multiple modes and multiple models together to perform complicated tasks. This way forward, in the near future, we can envision a world where humans have their own J.A.R.V.I.S !!
References:
[1] HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
https://arxiv.org/abs/2303.17580
[2] https://lilianweng.github.io/posts/2023-06-23-agent/

