What is image attribute extraction?
In the context of e-commerce products,image attributes can be thought of as meaningful information used to define a product.
Examples of such attributes: Color, Sleeve-type, Pattern, Neck-type, Length etc.
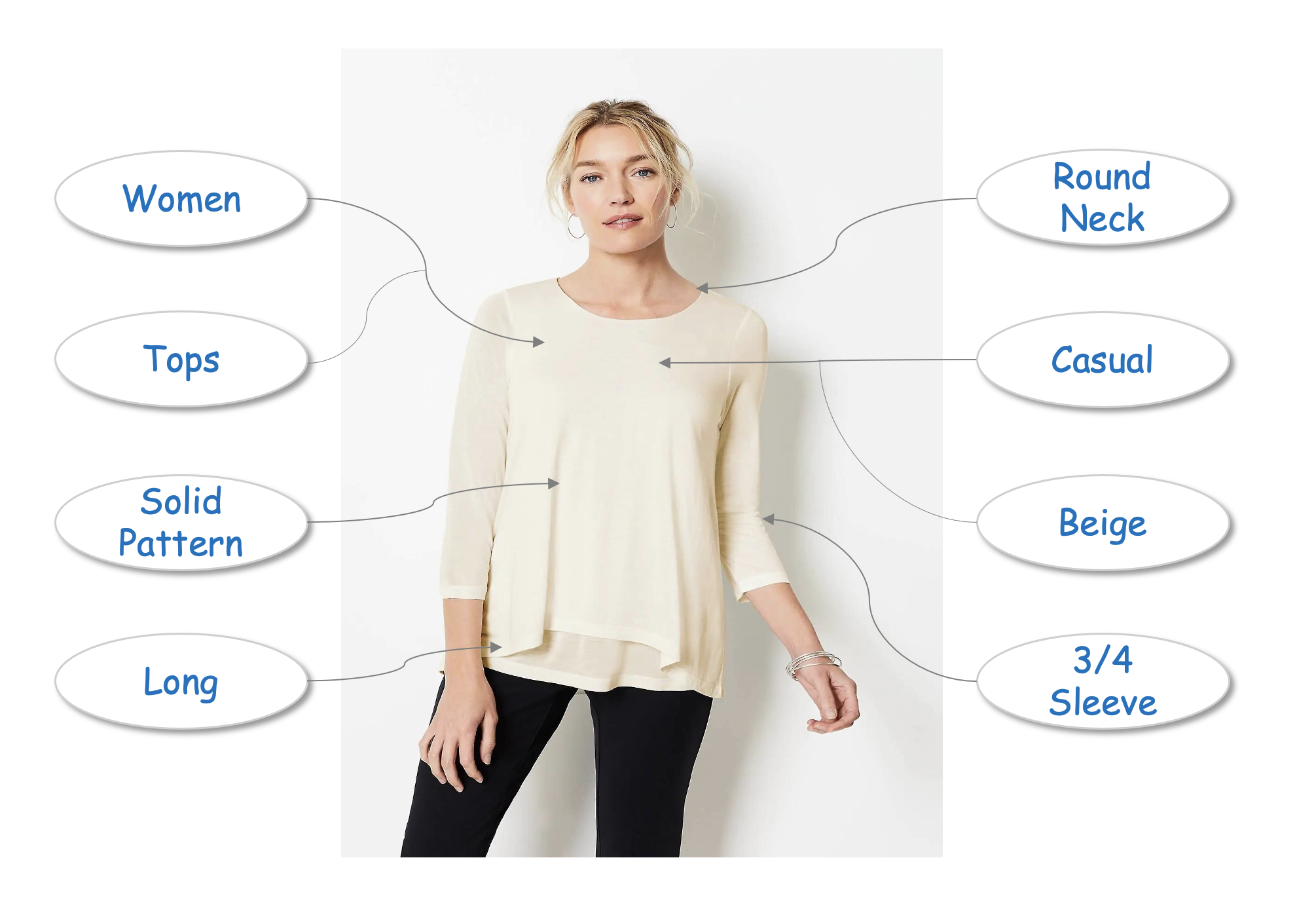
Fig1: Fashion Image Attributes
Image attribute extraction at Rakuten:
Fine-grained image attribute extraction from fashion images has diverse applications in e-commerce. Visual image attribute recognition is critical for fashion understanding, catalog enrichment, visual search, recommendations etc. We have designed an end-to-end framework for image attribute extraction from fashion wear images. We have used Rakuten's internal image repository to curate an image attribute dataset to train and validate our attribute extraction model.
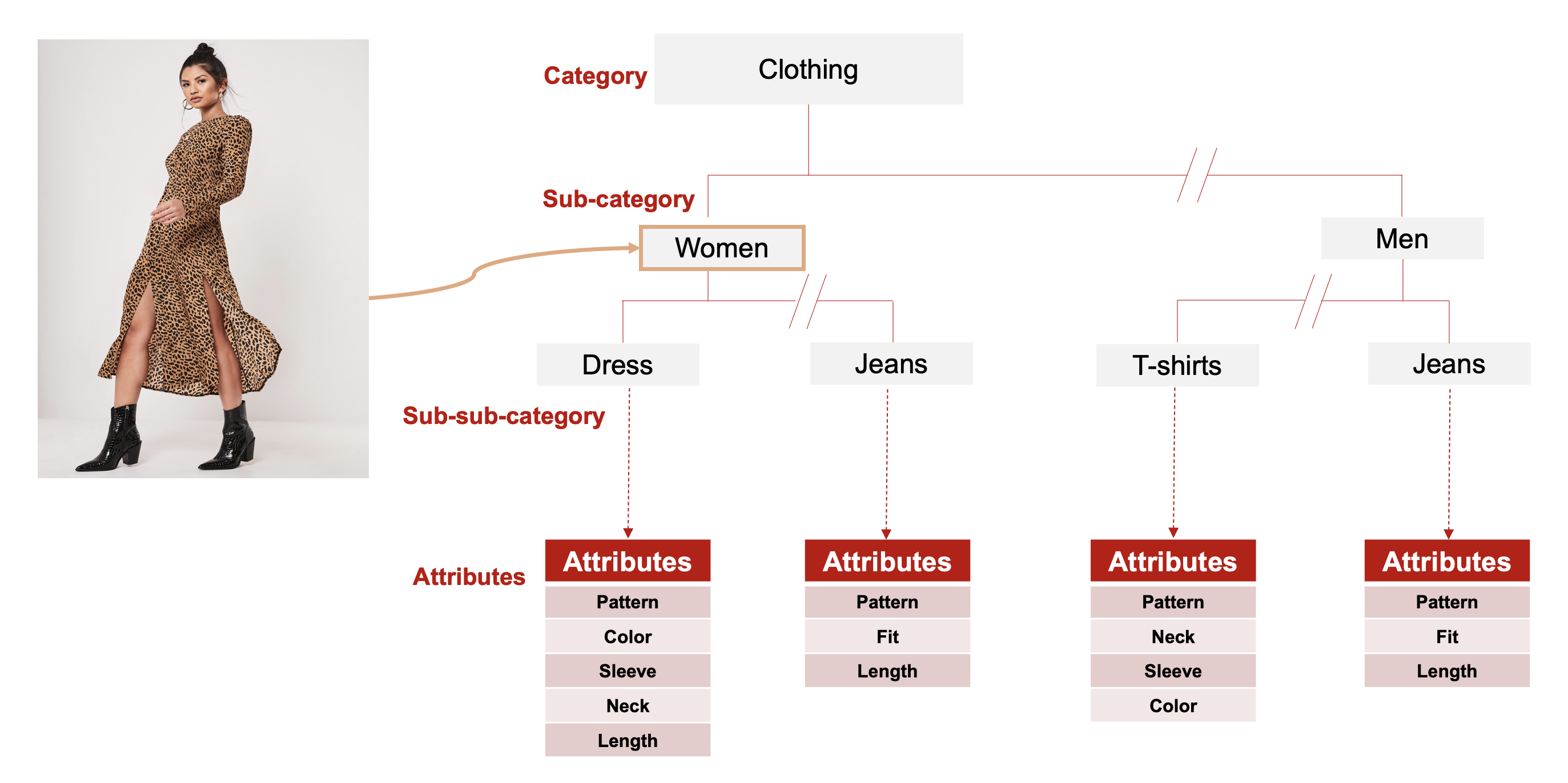
Fig2: Fashion Wear Product Catalog
Dataset:
This dataset includes widely varying categories, several levels of sub-categories, and fine-grained attributes etc. It consists of 533 leading product categories, which are then subdivided into several levels. After manual analysis of all these categories and subcategories, we curate our datasets. Fig 2 gives a brief overview of our extensive fashion image repository and its varied categories. For example, the clothing categories are sub-categorized based on gender, occasion, clothing style, apparel types etc. The visual attributes can be categorized based on different aspects such as for shoes: Type, Gender, Color, Heel Height, Heel Style, and for fashion wear: Type, Color, Pattern, Sleeve Type, Neck Type, Apparel Length etc. In order to design a fine-grained image attribute extraction framework, we created a new fashion wear attribute dataset using our internal image repository, which includes more than 500 category and sub-category groups.
Challenges:
We highlight few challenges faced during designing and executing the image extraction framework. Rakuten's internal image repository consists of millions of images, which is widespread over several levels of categories. It is a highly challenging task to curate a dataset from such a complex structure.
The dataset is highly challenging in terms of the following:
- Large number of categories
- Imbalanced data distribution at every level - category, sub-categories, attributes, and attribute values.
- Missing attributes
- Noisy attributes,
- Multi-labeled attributes.
- Insufficient data for certain segments of the dataset
Few strategies incorporated to tackle such complexities are:
- Manual analysis of the distribution of different category paths.
- Detailed inspection and selection of fine-grained attributes that model can extract with reasonable performance.
- Merge certain attribute values to help with model inferences (Eg: Neckline: round neck and scoop neck, as they look similar)
- Removal of duplicate, noisy and invalid images
Imbalanced Dataset:
The class imbalance problem is very prevalent in the field of machine learning and deep learning. For example, the image attributes length and neckline dataset include a varied number of datapoints distributed over all the attributes (classes) as shown in fig 3. There are several prominent methods for handling such class imbalance problems, such as various resampling techniques namely undersampling, oversampling, cluster-based oversampling, informed oversampling, modified synthetic minority oversampling technique (MSMOTE); ensemble methodologies including bagging, boosting, Ada Boost, XG boost, Gradient boosting based techniques; sample weighting schemes etc. We have used data augmentation based oversampling techniques to alleviate problems with class imbalance.
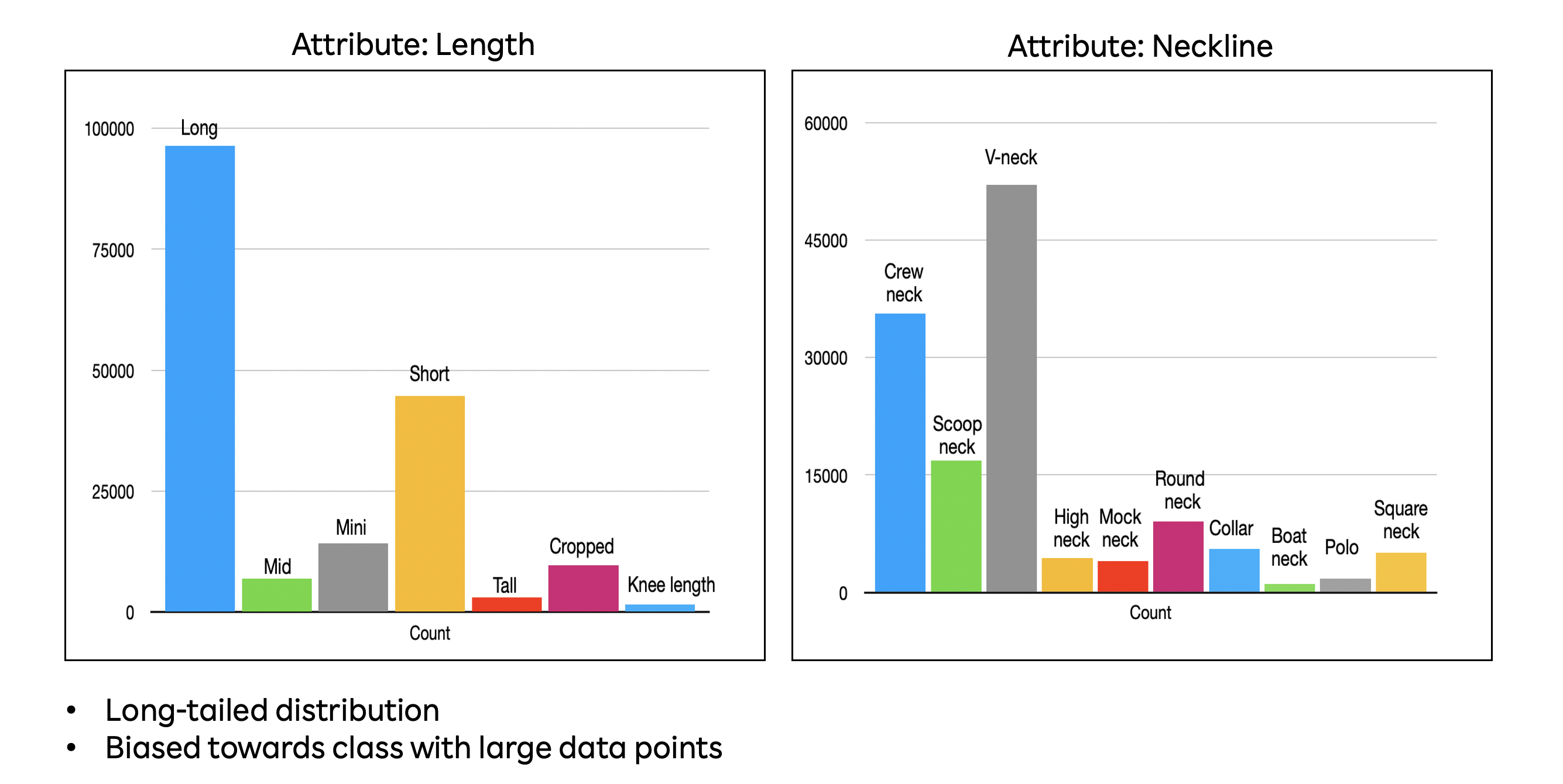
Fig3: Data Distribution of Neckline and Length Attributes
Missing Labels & Multi-labels:
Another frequently occurring problem is noisy and missing labels. It is very difficult to label and annotate all possible relevant information regarding any product into our product catalog. Even though most of our cataloged products go through many automated and manual annotation processes, still it is almost impossible to get meticulously labeled structured data. We automatically remove the duplicate, noisy and invalid images in our image pre-processing or data cleaning step before the train, validation, test split, and model training.

Fig4: Few Sample representing Missing, Noisy Labels
Proposed Framework:
Backbone Network:
We have conducted an extensive comparison of many state-of-the-art deep neural network architectures such as ResNet50, ResNet150, DenseNet121, EfficientNet-b0, EfficientNet-b7. In this work, we have used EfficientNet-b0 as the backbone network architecture. EfficientNet gave better performance compared to any other architecture, which motivated us to use it as the backbone architecture for our image attribute extraction framework. EfficientNet uniformly scales all dimensions of depth, width, and resolution using a compound coefficient or in other words a set of fixed scaling coefficients. Whereas most of the state-of-the-art architectures arbitrarily scale these factors. EfficientNet-B0 is based on the inverted bottleneck residual blocks of MobileNetV2, in addition to squeeze-and-excitation blocks. EfficientNets have achieved state-of-the-art performance on CIFAR-100 (91.7%), Flowers (98.8%), and 3 other transfer learning datasets.
Model Training:
We have used at least 1K images per attribute class. Each RGB image is resized to size 224x224 and associated with a label or class. The model training and validation were done with a batch size of 128. The instance used for this framework has a configuration of 8vCPUs with 30 GB RAM and the training was carried out using NVIDIA Tesla P100 GPUs.
Performance Metrics:
The proposed framework is evaluated in terms of Precision, Recall, and F1 Score.
Model Predictions & Visual Analysis:
Few sample image inferences as predicted by our image attribute extraction model are given below, along with the predicted confidence scores.


Where does the model look?
We plot below the Grad-Cam visualizations to illustrate where the model is looking at.


Conclusion:
In this article, we discuss the various challenges and steps involved in the image attribute extraction framework. This is a PyTorch model deployed in a Kubernetes environment that can scale to provide accurate predictions in relevant business use cases. Possible future directions of the current work are to extend this module to other relevant non-fashion categories.
That brings us to the end of this article. Hope you enjoyed reading it.
Useful Links:
EfficientNet paper: https://arxiv.org/abs/1905.11946

