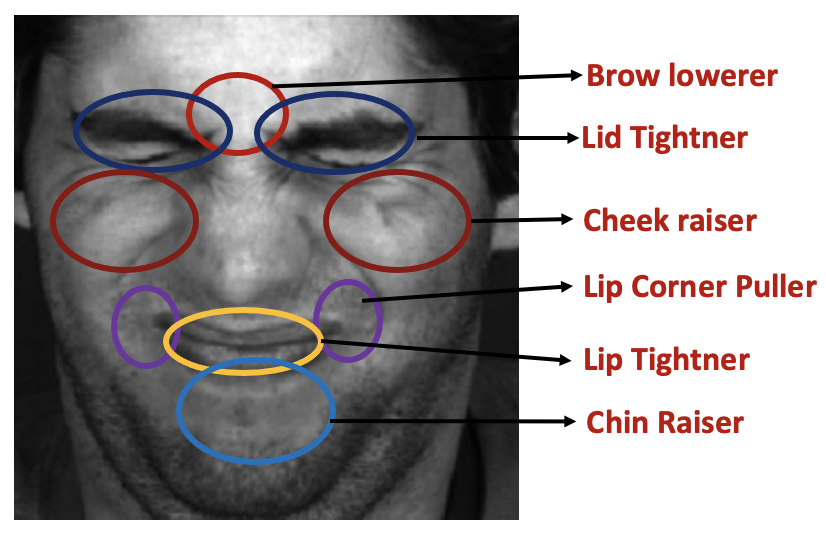
Motivation and methodology:
- Since action units are defined by particular muscle activations, the spatial extent of each action unit is limited.
- Also, FAUs are related with each other. For example, when the AU, Lip Corner Puller is active, there is high possibility that the AU Cheek Raiser is also active.
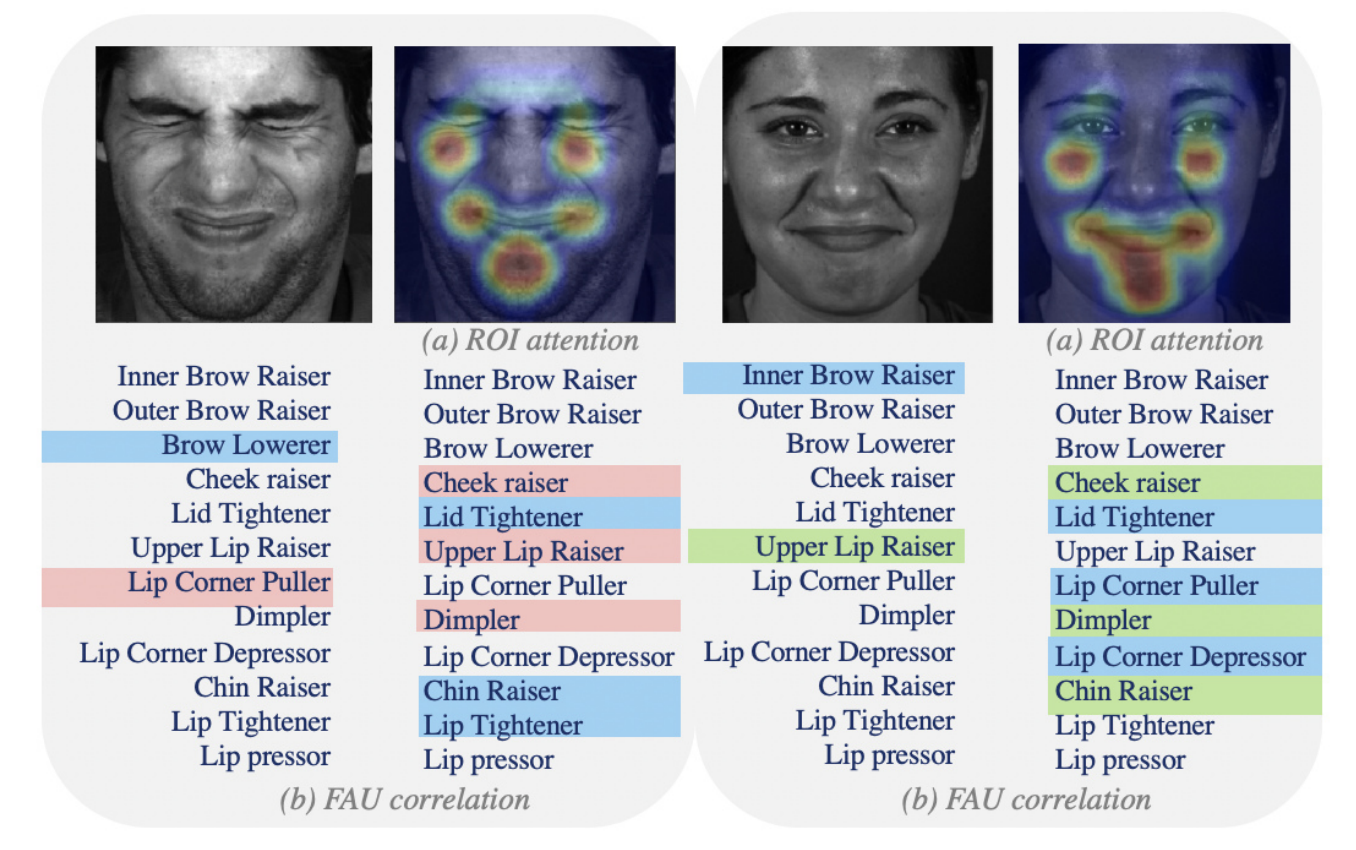
The figure above illustrates the two types of relationships we capture using our model. We model the spatial regions of individual action units using attention maps [ABN]((a)). We then capture the relationship between different action units by self-attention, using transformer encoders [Transformers] ((b)). In the figure, the spatial attention as well as the FAU correlations for two images are shown. The full list of AUs are listed to illustrate the AU correlations predicted by our model. Two sample active AUs are highlighted in the left and the corresponding correlated AUs are shown with the same colour on the right in each.
We propose an architecture which computes both the spatial attention as well as correlations between FAUs.
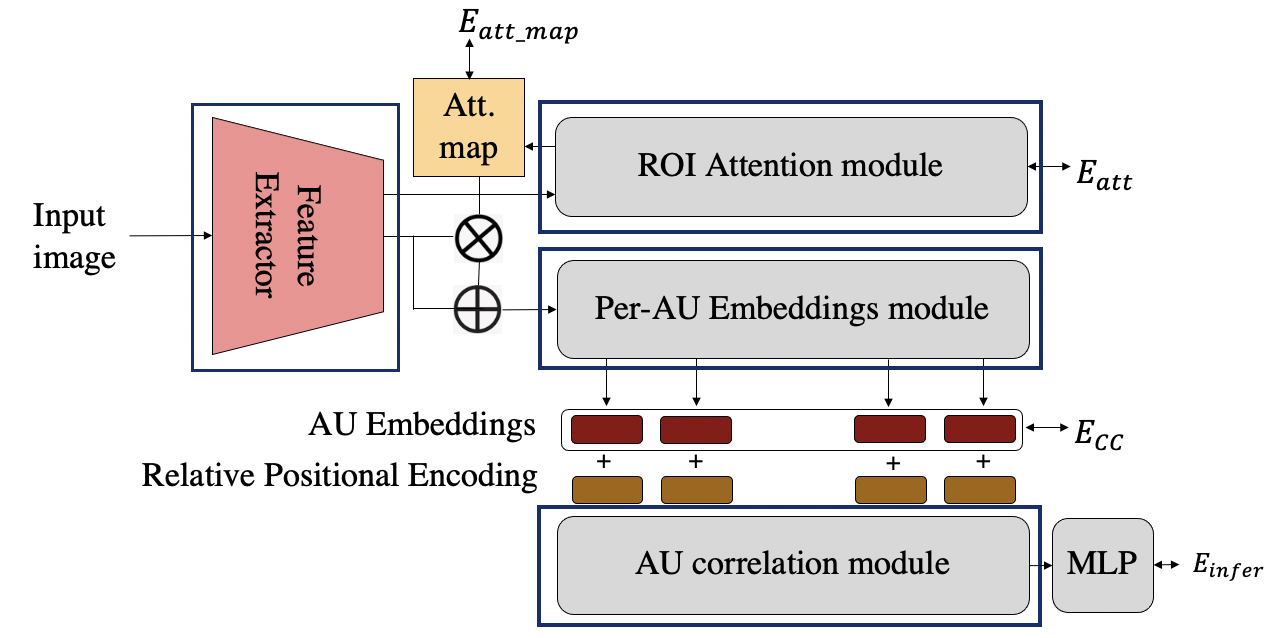
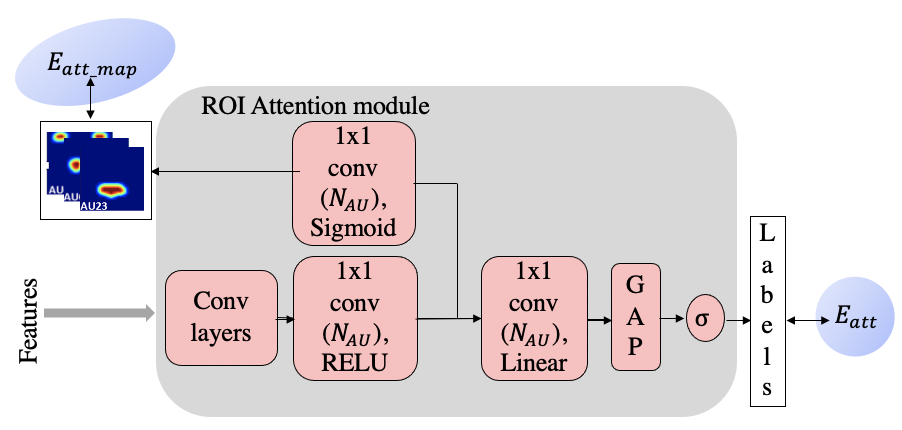
We use a InceptionV3 model pre-trained on imagenet as the feature extractor here. ROI attention module is built on the concept of attention branch networks [1]. The module takes features as input and learns attention maps for each action unit along with the labels associated with the face image.
There are two loss functions associated with this module.
In the first loss function,𝐸𝑎𝑡𝑡_𝑚𝑎𝑝, we provide a supervision on the attention map. The ground-truth for the attention map is created using facial landmarks.
The second loss function, 𝐸𝑎𝑡𝑡 is for the labels, where a combination of Cross Entropy loss and Tversky loss are used for providing supervision for the labels.
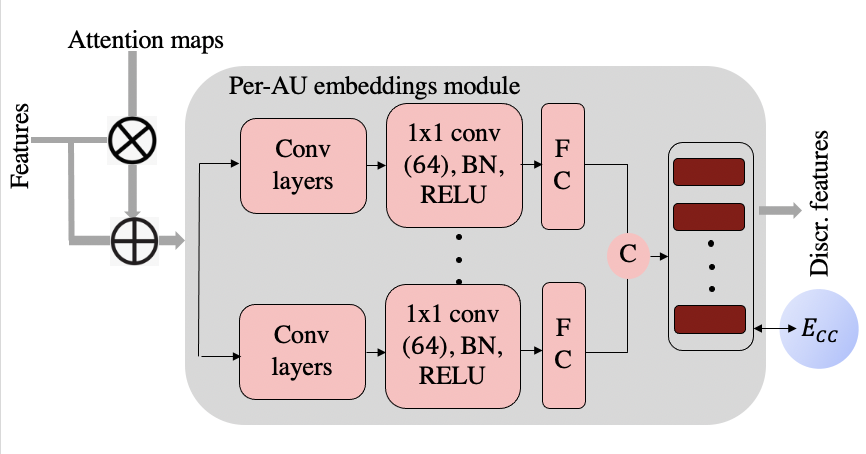
Per-AU embeddings module is basically a branched multi-task network, where each branch learn feature specific to each FAU. Here, the learned attention maps from the ROI attention module are weighted with the feature maps and provided as input to the module. The FAU-specific features are concatenated together and the proposed Center Contrastive loss,𝐸𝐶𝐶, makes them discriminative in nature. The CC loss formulation, minimises the intra-class variations of features, while maximising the inter class variations of features .

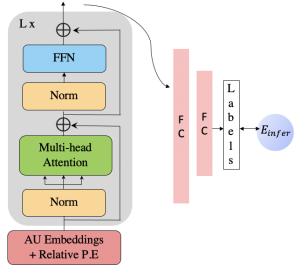
The AU correlation module, leverages the information of correlation between the FAUS. The module consists of L layers of transformer encoder [Transformers]. The discriminative features are fed to the transformer encoder, along with the positional encoding. The multi-head attention, computes self-attention, which estimates the importance of one FAU with respect to the other in each facial expression. The correlated features are now passes through an MLP consisting of fully connected layers, thus learning labels from the correlated and distinctive features. The loss function,𝐸𝑖𝑛𝑓𝑒𝑟, again is a combination of cross entropy loss and Tversky loss.
The model is trained end-to-end jointly minimising all the loss functions together. Thus the final loss function, 𝐸(𝑥) is
𝐸(𝑥)=𝜆1𝐸𝑎𝑡𝑡(𝑥)+𝜆2𝐸𝑖𝑛𝑓𝑒𝑟(𝑥)+𝜆3𝐸𝑎𝑡𝑡_𝑚𝑎𝑝(𝑥)+𝜆4𝐸𝐶𝐶(𝑥),
where 𝜆1 to 𝜆4 are hyper-parameters empirically selected.
Some qualitative examples
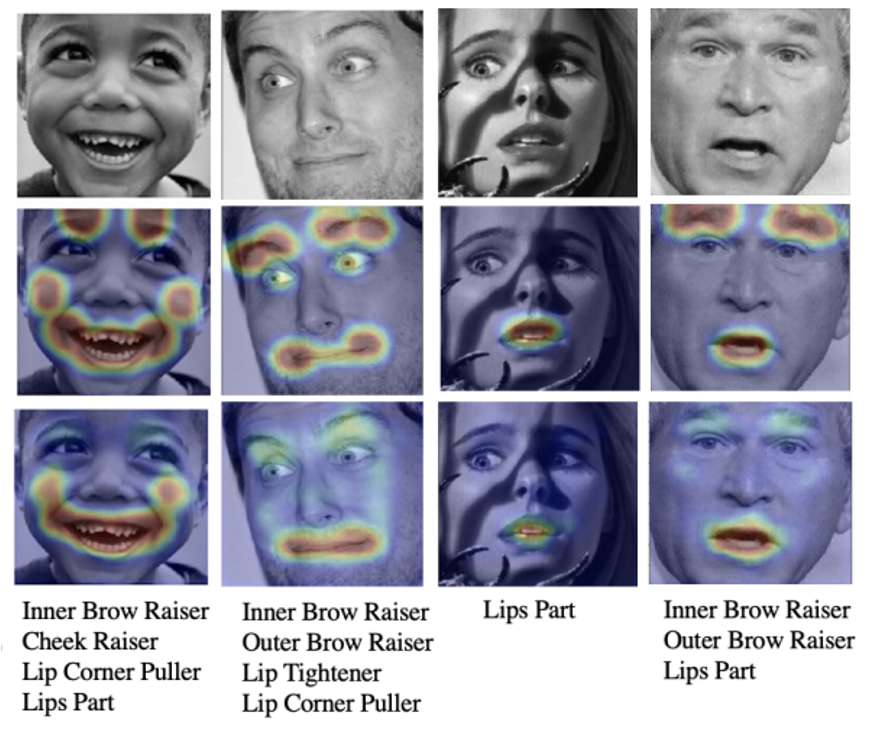
The figure below shows some qualitative results on 4 examples. The first row shows the input images, the second row shows the ground-truth attention map obtained using facial landmarks, the third row shows that attention map extracted by our model and the fourth row shows the action units predicted by our model.
Some business use-cases:
Rakuten research (User study analysis) based on facial expression analysis
- Extract desired expression from video. Eg: ((smile), (sad), (big grin), …)
- Extract best shot from user videos
- Ad placement using feedback signals from user
Useful links
Paper link: https://openaccess.thecvf.com/content/CVPR2021/papers/Jacob_Facial_Action_Unit_Detection_With_Transformers_CVPR_2021_paper.pdf
Video link:

